
PatentNext Takeaway: When deciding whether to patent AI-based inventions or maintain them as trade secrets, key considerations include the extent of public disclosure and the detectability of the AI model. Deploying an AI model in consumer-facing devices or making its output public often supports patenting to secure exclusivity. On the other hand, low detectability and sensitive training data, such as personal or medical information, may favor trade secret protection. Balancing these factors alongside the need for sufficient disclosure to meet patent requirements allows businesses to safeguard their innovations while mitigating risks.
****
Introduction
Modern uses of AI can include the private use of AI models trained to assist businesses in making decisions and guiding internal processes. Such modern uses can also include the deployment of AI models on devices for consumer use. This article discusses factors to consider when determining whether to patent AI-related inventions or keep them as trade secrets. These factors generally rely on issues such as how public the AI model in question will become, including its output, and where and how it will be deployed, if at all.
Typical AI-Based Modeling and Device Deployment Scenario
The graphic below illustrates typical AI-based modeling and AI-based device deployment scenarios. In particular, the items above the red-dotted line (labeled “Public Disclosure”) illustrate the deployment of a trained model to a publicly available AI-based device. The AI-based device could use the trained AI model on the device’s computer memory, and the device could supply data input (e.g., sensor data) to the AI-based device, which, in turn, could provide data output. For example, the AI-based device may be a consumer device that uses the deployed AI model to take input (e.g., from sensors on the device) and produce an output (e.g., generate a prediction for the user while the user is using the device).
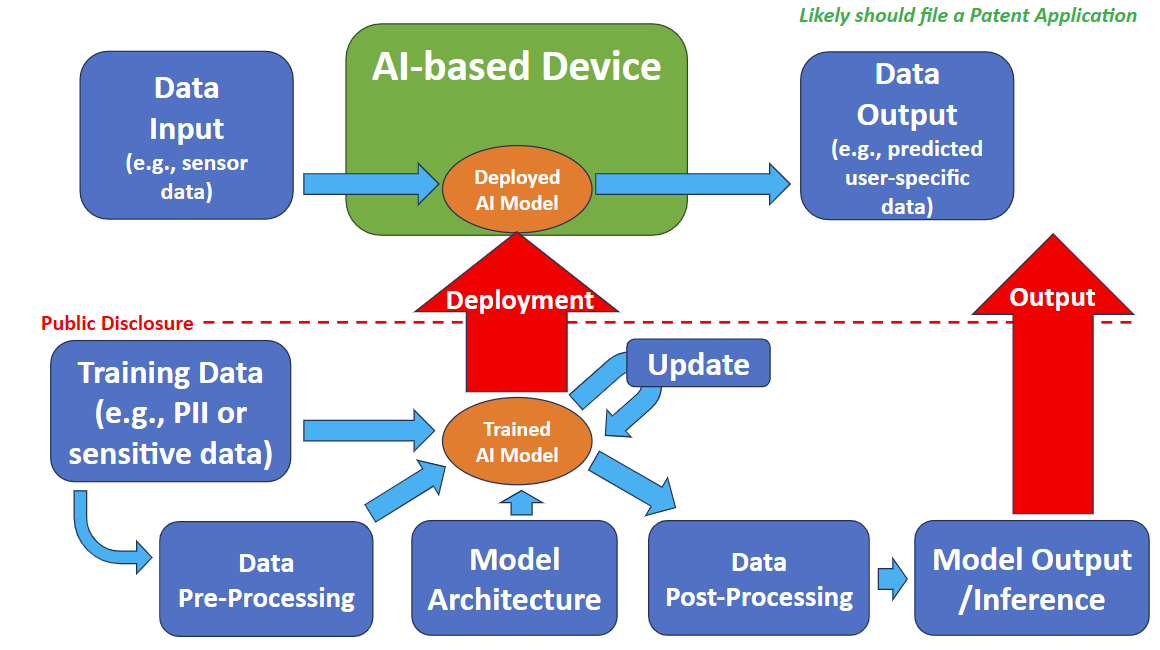
The above graphic also shows typical steps related to training a related AI model. These steps are shown below the red-dotted line. Each of these steps typically includes considerations that can help inform whether to file a patent. These steps and related considerations include the following:
- Training Data: Gathering and storing raw data used to train an AI model. Considerations for this step may include: How was the data collected? What hardware (e.g., sensors) was used to collect the data? What is the format of the data when it is collected?
- Data Pre-processing: Formatting the raw training data to prepare it for AI modeling. Considerations for this step may include: Does the raw data create issues for training? Is raw data preprocessed before being used for training? Does the format of the data change between being collected and being used by the model? If so, how?
- Model Architecture: Selecting a model architecture for training the AI model with the training data. Considerations for this step may include: What type of model architecture will be used? Examples include Neural Network (NN) architecture, convolutional NN (CNN) architecture, recurrent NN (RNN) architecture, or large language model (LLM) architecture, etc. What type of training will be used, e.g., supervised learning, reinforcement learning, etc.? Will an “off-the-shelf” (i.e., existing) AI model or algorithm be used to train the model? Are there proprietary aspects to developing, training, and/or processing the AI model? Does the number of layers matter? Will there be any hyperparameter tuning? Will the model architecture use multiple models (ensemble models or a multi-modal architecture)?
- Update: Updating the model with new and/or additional training data to create a new version or generation. Considerations for this step may include: How is the model retrained or updated with new data?
- Data Post-Processing: Formatting the output of the trained AI model. Considerations for this step may include: Is the output data manipulated, transformed, or otherwise modified to be used by the AI-based device or by downstream functions utilizing the output of the AI-based device?
- Model Output/Inference: Analyzing the output of the AI model and using it for end-use purposes. Considerations for this step may include: What form or format does the output of the AI model take? What process does the trained AI model require to make predictions when provided with new data?
Each of the above AI training-related steps can help inform whether to file a patent. This is further discussed below.
Factors that Favor the Filing of a Patent Application
Generally, when the AI model and/or its output is made public, it increases the likelihood that a patent should be filed to protect a given invention.
First, with reference to the above graphic, if the trained AI model is deployed as part of an AI-based device, such a scenario typically suggests that a patent application should be filed. In such cases, the AI-based device can have a copy of the AI-based model stored in its memory. In these scenarios, the AI-based model could be considered “publicly disclosed” when the AI-based device is made public, e.g., when it is sold.
Second, and with further reference to the above graphic, an entity considering the pursuit of patent protection should ask: When the AI model is used by the company internally, does the output of the AI model comprise solely internal company use? If not, then patent protection should be considered. For example, even if a trained AI model is kept private (e.g., on company servers or computers), does its output become public through the company’s marketing materials or otherwise as a report or other information? The Federal Circuit case Quest Integrity USA, LLC v. Cokebusters USA Inc. provides an example of how the output of an AI model could create potential issues (924 F.3d 1220, 1227-28 (Fed. Cir. 2019)).
The Quest Integrity case illustrates an example where a company’s offer to use (and actual use of) a process before the critical date invalidated a patented claim to the process under the on-sale bar of § 102(b). Such invalidation occurred even though the company may not have actually offered to sell the process itself to the customer. While Quest Integrity does not involve AI, it does showcase that a process using AI could negatively impact patent rights, e.g., where the output from a given AI model is used as part of the process.
In Quest Integrity, the Federal Circuit affirmed summary judgment of invalidity for an on-sale bar of a claimed process. The patentee (Quest), before the critical date, had sold its furnace inspection services to at least one customer and used the claimed process in performing the sold service, even though the patentee had not sold the customer any equipment or software. The Federal Circuit nonetheless found that “[t]he fact that Quest did not sell its furnace inspection hardware or software (i.e., its method, computer-readable medium, or system) does not take Quest’s commercial activities outside the on-sale bar rule.” Id.
Importantly, the court focused on the output of the process. In particular, the court found that the output (i.e., “Norco Reports”) as produced by Quest’s process triggered the on-sale bar, e.g., “Rather, Quest used its method, computer-readable medium, and system commercially to perform furnace inspection services and produce the Norco Reports for its customer. Sale of a product (here, sale of the Norco Reports) produced by performing a claimed process implicates the on-sale bar.” Id.
The output of the process triggered the on-sale bar even though the underlying system was not sold or offered for sale, e.g., “Performance of a claimed method for compensation, or a commercial offer to perform the method, can also trigger the on-sale bar, even where no product is sold or offered for sale. As we held in Scaltech, ‘[t]he on-sale bar rule applies to the sale of an “invention,” and in this case, the invention was a process.’” Id.
Further, the output of the process triggered the on-sale bar even though the output itself consisted of only a portion of the system and the claimed process, e.g., “The same approach [as the Scaltech case] necessarily applies where a service (here, furnace tube inspection) is performed for compensation using a claimed computer-readable medium or system that generates a ‘product’ (here, the Norco Reports).” Id.
Thus, the Quest Integrity court found that the output (e.g., the Norco Reports) of the claimed system triggered the on-sale bar, invalidating the patent in question because it was filed too late.
A similar situation could arise where a trained AI model, even when used internally at a company, produces an output (e.g., like the Norco Reports). If such output is sold as part of a process or system, then the on-sale bar could apply. Such a factor could weigh in favor of seeking patent protection.
Other Factors: Patent vs. Trade Secret Considerations
Other factors also weigh on whether an AI-related invention could be a candidate for patenting or whether such an invention should remain a trade secret. These include the following:
- Detectability: Can a given AI model be detected? For example, would a competitor use the AI model, and, if so, would the use of the AI model be recognizable from the competitor’s marketing materials, technical manuals, white papers, or the like? If there is no or low detectability, this weighs in favor of not patenting a given AI invention and instead keeping it a trade secret.
- Sensitivity of Training Data: Is the training data used to train the AI model highly sensitive, such as personally identifiable information (PII) or medical data (e.g., HIPAA data)? Will the model output predictions or classifications based on such data? The closer the AI model is to using and outputting sensitive data in its raw or original form, the more it weighs in favor of keeping the AI model as a trade secret. However, AI model developers can make such sensitive information generic or abstract by either removing sensitive data or creating mock or synthetic data for training. If this can be achieved, then this factor weighs in favor of patenting the given AI invention.
- Need for Patent Disclosure vs. Disclosing Related Trade Secret Information: Because of all the steps involved in training and using a given AI model, multiple types or forms of trade secrets can be involved. For example, as discussed above, training data could involve lists of consumer information. A question arises as to how much and what kind of data is sufficient. For example, 35 U.S.C. § 112 requires sufficient disclosure to show that an inventor “possesses” the invention (written description requirement). Section 112 also requires sufficient disclosure to allow those of skill in the art to practice the invention without undue experimentation. Further, while 35 U.S.C. § 101 does not require any specific disclosure, it is typically a best practice to disclose sufficient details to hallmark a “practical application” such as an “improvement” to the underlying computing device. See, e.g., PatentNext: Intelligence (AI) Invention: Guidance from the U.S. Patent Office (USPTO). Further, details of the AI model may need to be disclosed to ensure that the written description has sufficient material to support embodiments that may prove useful in overcoming prior art from the perspective of Section 102 (novelty) and Section 103 (obviousness). These considerations should be balanced where a need for sufficient disclosure in the patent application to satisfy one or more of these statutory requirements could be weighed against the desire to disclose such information, which might otherwise remain as a trade secret.
Conclusion
In deciding between patenting and maintaining trade secrecy for AI-based inventions, a careful evaluation of several factors is essential. Public disclosure, either through the deployment of an AI model in consumer-facing devices or the visibility of its output, often leans toward seeking patent protection to safeguard the invention. Conversely, scenarios involving low detectability, sensitive training data, or a need to limit disclosure favor retaining the invention as a trade secret.
The decision also hinges on the balance between the benefits of patent exclusivity and the risks associated with revealing proprietary information in patent filings. Ultimately, businesses must weigh the specifics of their AI model’s use, its detectability by competitors, and the nature of its training and operational data to choose the strategy that best aligns with their goals and risk tolerance. By addressing these considerations, organizations can better protect their AI innovations while navigating complex legal and competitive landscapes.
****
Subscribe to get updates to this post or to receive future posts from PatentNext. Start a discussion or reach out to the author, Ryan Phelan, at rphelan@marshallip.com (Tel: 312-474-6607). Connect with or follow Ryan on LinkedIn.